0%
Theme NexT works best with JavaScript enabled
开篇不知道写啥
该篇文章主要记录了C语言函数调用以及相关应用的一些想法. 如果你问我为什么要写这篇博客, 这一切都要从一只可爱的蝙蝠说起……
测试环境
ubuntu20.04
gcc (Ubuntu 9.3.0-10ubuntu2) 9.3.0
C语言中函数调用过程 X86架构下函数调用分析
我们先写一个简单的demo1 2 3 4 5 6 7 8 9 10 #include <stdio.h> int add (int x, int y) int sum = x + y; return sum; } int main (int argc, char *argv[]) int sum = add(2 , 3 ); printf ("sum: %d\n" , sum); return 0 ; }
使用 gcc -m32 -O0 -g demo.c 编译, 然后使用 objdump 反汇编一手看看对应的汇编代码1 gcc -m32 -O0 -g demo.c && objdump -d a.out
main 函数的代码(我们只截取和我们相关的部分)1 2 3 4 5 6 7 8 9 10 11 12 13 14 000011 f1 <main>: .... 1212 : 6 a 03 push $0x3 1214 : 6 a 02 push $0x2 1216 : e8 b2 ff ff ff call 11 cd <add> 121 b: 83 c4 08 add $0x8 ,%esp 121 e: 89 45 f4 mov %eax,-0xc (%ebp) 1221 : 83 ec 08 sub $0x8 ,%esp 1224 : ff 75 f4 pushl -0xc (%ebp) 1227 : 8 d 83 30 e0 ff ff lea -0x1fd0 (%ebx),%eax 122 d: 50 push %eax 122 e: e8 3 d fe ff ff call 1070 <printf@plt> .... 1244 : c3 ret
1216 处, 我们可以直接看到 main 函数调用了 add 函数, 即 call 11cd <add>, 我们再看 call 指令之前的两条指令, 分别是 push $0x3 和 push $0x2 , 这个我们熟悉啊, 这不就是我们源码中 add(2, 3) 操作的两个参数嘛.call 指令调用对应的函数. add 函数的汇编代码1 2 3 4 5 6 7 8 9 10 11 12 13 14 000011 cd <add>: 11 cd: f3 0 f 1 e fb endbr32 11 d1: 55 push %ebp 11 d2: 89 e5 mov %esp,%ebp 11 d4: 83 ec 10 sub $0x10 ,%esp 11 d7: e8 69 00 00 00 call 1245 <__x86.get_pc_thunk.ax> 11 dc: 05 fc 2 d 00 00 add $0x2dfc ,%eax 11e1 : 8 b 55 08 mov 0x8 (%ebp),%edx 11e4 : 8 b 45 0 c mov 0xc (%ebp),%eax 11e7 : 01 d0 add %edx,%eax 11e9 : 89 45 fc mov %eax,-0x4 (%ebp) 11 ec: 8 b 45 fc mov -0x4 (%ebp),%eax 11 ef: c9 leave 11 f0: c3 ret
add 函数中, 我们做的事很简单, x 和 y求和, 查看 add 函数的汇编代码, 和 两数相加 有关的操作只有地址为 11dc 和 11e7 两处, 我们使用排除法, 首先必不可能是除了 11dc 和 11e7 以外的指令(开个玩笑, 其实相加操作是 11e7 处的指令)11e7 处的指令 add %edx, %eax, edx 和 eax 寄存器中应该就是 x 和 y 的值了, 再查看 11e1 和 11e4 处两条指令, 看样子 edx 和 eax 中的值分别来自 0x8(%ebp) 和 0xc(%ebp) , 下面是执行到 11d2 指令处处栈的情况:1 2 3 4 |-----3------| <------- y |-----2------| <------- x, 1216 之前两条push指令的结果 |----eip-----| <------- 执行 1216 地址处 call 命令会将eip压到栈中 |---old ebp--| <------- 执行到 11e1 时 ebp 的指向.
32位 编译该程序, 栈中每个元素占4字节 , 所以 0x8(%ebp) 指向参数x, 0xc(%ebp) 指向参数y. 现在函数参数的问题已经解决了, 那 add 函数的返回值存放在哪里呢? 分析 11e1 到 11ec 的指令, 最后 x+y 的值似乎存放在了 eax 中? 没错, add 函数的返回值就是通过eax 返回给调用方的!
现在我们知道了, 在X86架构下C语言中函数调用前会将必要的参数压栈, 被调函数执行时会从栈中取得参数, 最后被调函数将返回值放到 eax 中返回给调用方
X86-64架构下的情况
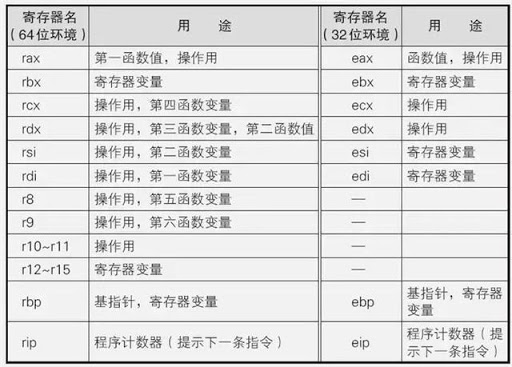
x86-64架构下的情况与x86有所不同, 看下图.
X86-64架构下C函数调用时会首先将寄存器当做参数传递给被调函数, rdi 作为第一个参数, rsi 是第二个, 其余的以此类推. 但是作为函数参数的寄存器总共有6个, 当参数超过6个时, 就和X86 一样通过栈传递参数(注意参数从右向左入栈)
另外, 函数的返回值由 eax 变成了 rax .
总结
x86下使用栈进行参数传递, 使用eax 作为返回值, x86-64下优先使用寄存器传递参数, 如果参数较多则使用栈, 使用rax 作为返回值
ps: 以上讨论的都是大多数, 或者通常情况下的处理方法. 在其他情况下, 比如说参数或返回值是浮点数, 返回值太大需要多个寄存器等都会有其他处理方法.
知道了”函数调用”也没什么卵用系列 热身
好了, 现在我们已经了解了C语言中函数调用时发生的事, 可是……
emmmmm, 上面罗里吧嗦说了一大堆, 了解了”函数调用”我们具体能做什么呢? 首先让我们手工模拟一下函数调用的过程.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdio.h> int add (int x, int y) int sum = x + y; printf ("%d + %d = %d\n" , x, y, sum); return sum; } int main (int argc, char *argv[]) int res = 0 ; void (*fuck)() = add; asm volatile ("pushl $3; pushl $2;" ) fuck(); asm volatile ("" :"=a" (res):) printf ("eax's value: %d\n" , res); return 0 ; }
和之前不同的是, 这次我们使用 asm volatile("pushl $3; pushl $2;"); 手工将参数压栈, 让函数指针fuck指向add函数, 这样fuck执行时就只会将返回地址压栈, 最后我们使用 asm volatile("":"=a"(res):); 手工将eax中的值取到res中. 编译执行它看看结果1 2 3 > >> gcc -m32 demo.c && ./a.out 2 + 3 = 5 eax's value: 5
正如我们所预料的, it works well! 可是……
system call: every different
众所周知, linux使用int 0x80进行系统调用, eax 存放系统调用号, 其他的几个寄存器(和具体的平台有关)存放参数, linux0.11 中最多只有3个参数, 使用 ebx, ecx, edx存放参数, 而现在的最多可以传递6个参数
假设你现在正在开发自己的kernel , 同样使用 int 0x80 进行系统调用, 同样使用ebx, ecx, edx传递参数, 假设系统调用中断进入的函数是 system_call, 当我们对”函数调用”不熟悉的时候, 我们写出来的代码可能是类似这样的:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void system_call(){ number = eax; arg1 = ebx; arg2 = ecx; arg3 = edx; if(number == 0){ sys_call0(); else if(number == 1){ sys_call1(arg1); }else if(number == 2){ sys_call2(arg1, arg2); }else if(number == 3){ sys_call3(arg1, arg2, arg3); } ...... }
emmmm, 看到这堆代码, 怎么感觉……
没错, 是菜鸟本菜无误了! 如果我们看了linux0.11 中的处理, 理解函数调用, 我们就懂了, 其实可以写成这样:1 2 3 4 5 6 7 8 9 10 system_call(){ ...... push edx push ecx push ebx call syscall_table[eax] ...... } typedef void (*syscall)(); syscall syscall_table = { sys_call0, syscall1, .....}
我们为什么没有想到这么做? 根据eax的值选择对应的处理函数, 我们其实能想到使用数组, 到时候直接执行syscall_table[eax] 对应的函数多好, 问题就在于每一个系统调用对应的处理函数参数不固定, 所以我们首先将所有可以携带参数的寄存器压栈, 然后直接调用syscall_table[eax]对应的函数, 就像上次手工模拟的那样(先将参数3和2push到栈中,然后fuck())
你不知道的printf
对C语言研究不深的同学(琪….琪玉同学?), 可能不清楚printf的实现, 想一下我们既可以 printf(“%s”, “Hello”) , 也能printf(“%s, %s”, “Hello”, “World”) , 也就是说printf函数接受可变参数. 我们可以在函数声明中使用 … 来表示该函数接受可变参数, C语言中提供了相应的库来帮助我们获取参数, 具体可见这里 . 但是我们现在不用这些库, 我们还是手工模拟一下.
我们现在立刻试着实现一下print 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <stdio.h> void print (char *fmt, ...) unsigned int *args = (unsigned int *)(&fmt) + 1 ; while (*fmt){ if (*fmt != '%' ){ printf ("%c" , *fmt++); continue ; } switch (*++fmt){ case 's' : printf ("%s" , (char *)(*args++)); fmt++; break ; default : printf ("%c%c" , '%' , *fmt++); break ; } } } int main (int argc, char *argv[]) print("%s, %s\n" , "Hello" , "World!" ); return 0 ; }
编译执行后应该会看到以下结果1 2 > >> gcc -m32 demo.c && ./a,out Hello, World!
想一下函数调用的过程, 被调函数的参数从右到左被压入栈中, 我们只要知道了最左边那个参数的位置, 就相当于知道了所有参数的位置, 那么自然就可以获得参数的值. 上面我们借助printf实现我们自己的print, 不过当你开发一个kernel 的时候肯定会实现屏幕输出的接口, 到时候只需要将printf替换一下就OK了. 实际上, 一种实现可能是这样的 :1 2 3 4 5 6 void print (char *fmt, ...) char buffer[256 ]; vsprintf (buffer, fmt, args); put_str(buffer); }
emmmmm, 好像有点意思
Reference
Linux内核函数调用规范 Linux的系统调用