CS61B
CS61B
即使你只做过Proj0, 还未开始其他的HW, lab和Project, 也能立刻体会到这门课的精彩。
无关算法-真正开始之前 Proj0: A crash course in Java
Project0无关算法, 它会让你使用Java做一个模拟lab, 简而言之, 你会在两周之内了解Java, Git, Unit Testing等知识, 之后做一个小项目(反观国内, 很多大学要开一学期的Java语法课, 做着无聊透顶的CRUD, 最后还要做题考试), 项目很简单, 但学到的不止是语法
- 如何完成一个Big thing? 先从小的地方开始, 为了完成这个项目, 你会从最简单的构造函数开始一步一步设计API, 每一个API又会用到你之前写好的API, 从底层一直抽象到上层, 直到完成我们的目标。
- 如何保证你的程序是正确的? 从第一步开始, 你的每一小步都要经过测试, 最终保证整个程序的正确性。
最后你会看到星球运转的模拟动画, 不懂物理的程序员不是好的程序员 :)
Double Ended Queue
在Proj1A中要基于数组和链表设计双端队列。
LinkedListDeque
基于链表设计时, 两端添加, 删除节点时间复杂度为 O(1), 但 get(index) 操作时间复杂度为 O(n).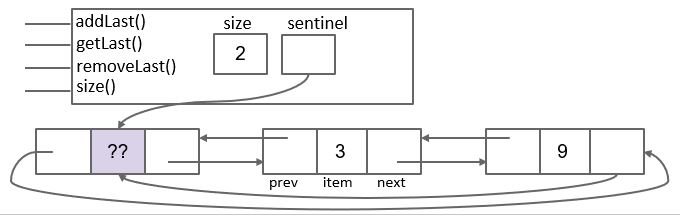
ArrayDeque
基于数组设计时两端添加, 删除节点, get(index)操作的时间复杂度都可以是 O(1), 但是存在 resize array(数组填满时resize成大数组, 删除过多元素后resize成小数组) 的问题.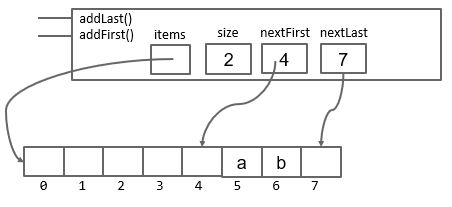
little tips
- Java pass by value.
When you write y = x, you are telling the Java interpreter to copy the bits from x into y. When you pass parameters to a function, you are also simply copying the bits. Copying the bits is usually called “pass by value”. In Java, we always pass by value. - 减少special case.
A cleaner, though less obvious solution, is to make it so that all SLLists are the “same”, even if they are empty. We can do this by creating a special node that is always there, which we will call a sentinel node. The sentinel node will hold a value, which we won’t care about. - 练习: leetcode 622.设计循环队列 leetcode 641. 设计循环双端队列
Proj2
pass
Union Find
在计算机科学中, 并查集是一种树型的数据结构, 用于处理一些不交集(Disjoint Sets)的合并及查询问题.
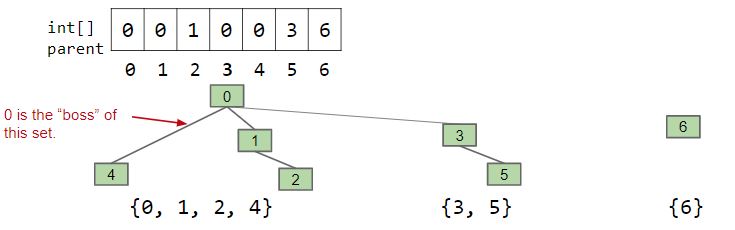
1 | class UnionFind(object): |
Tree
BST
线性链表的查询时间复杂度为 O(n), 为了加快查找, 可以使用二叉搜索树, BST的查找, 插入复杂度都为 O(logN)
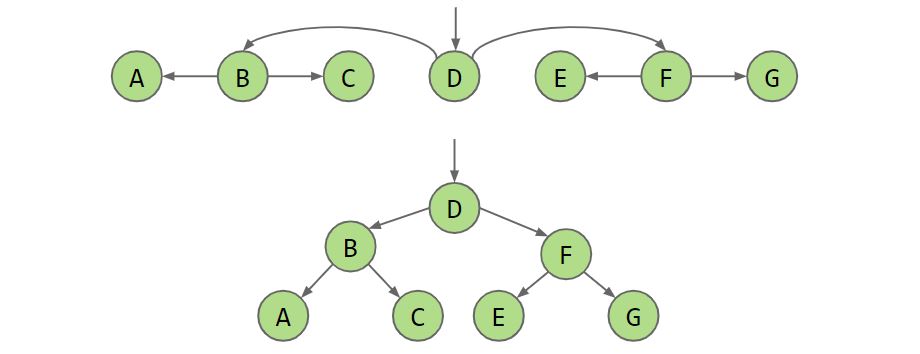
BST在最坏的情况下会退化成链表(升序插入节点), 为了 平衡 这颗树, 我们可以通过旋转操作来平衡BST, 也可以通过Split操作平衡BST。
B-Trees
可以使用Split Node的方式平衡一棵树, 即B-Trees, B-Trees是严格意义上的平衡树, 一个节点中可以有多个值, 当一个节点中的元素达到最大数量时Split该节点. 下图是一颗2-3树(tree node可以有2, 3个子节点)插入数据时的Split行为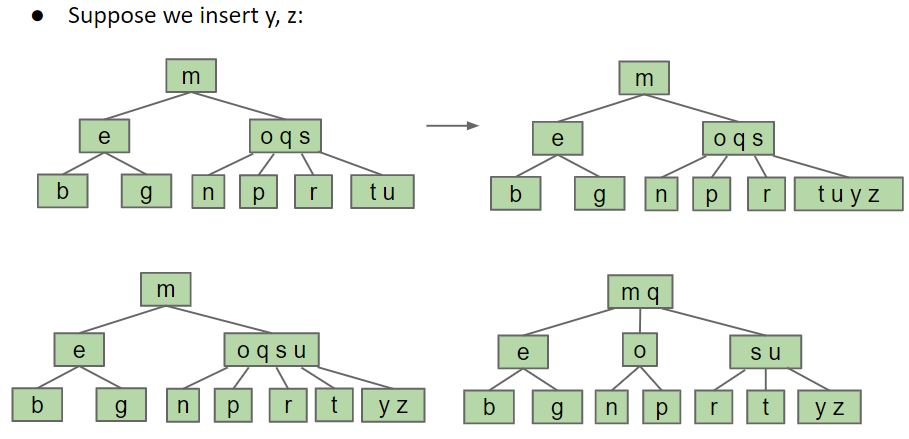
B-Trees一般用于数据库索引中, 每个节点容纳值通常很大.
Red-Black Trees
也可以通过旋转操作来平衡一颗Tree, 但Red-Black Trees并不是严格意义上的平衡树, 而是perfectly black balanced. 把红黑树的Red links水平放置后其实就相当于B-Trees.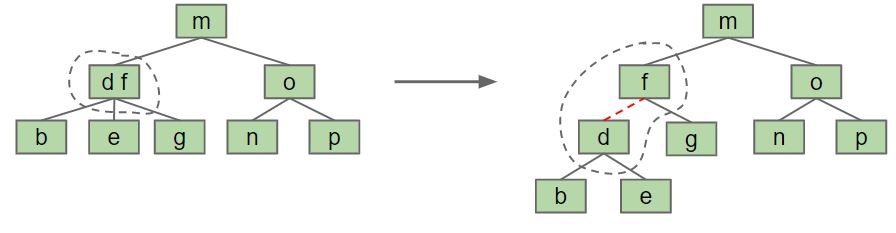
平衡树PPT
Hashing
散列表(Hash table, 也叫哈希表), 是根据键(Key)而直接访问在内存储存位置的数据结构。也就是说, 它通过计算一个关于键值的函数, 将所需查询的数据映射到表中一个位置来访问记录, 这加快了查找速度。这个映射函数称做散列函数, 存放记录的数组称做散列表。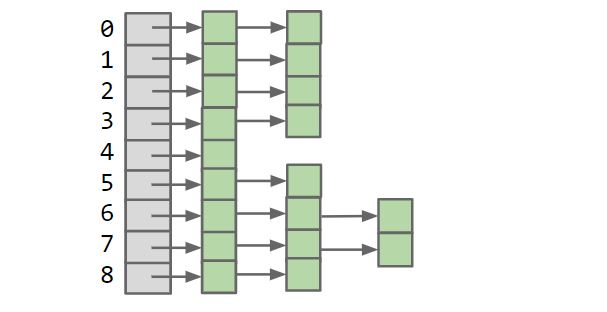
- 散列函数: 每个对象都有对应的HashCode, 可以根据取余法获得Index
- 解决冲突: 链表法, 开放地址法
- 负载因子: load factor = 填入表中的元素个数 / 散列表的长度, 一般在大于0.75时resize散列表
Example: Hashing a Collection
@Override
public int hashCode() {
int hashCode = 1;
for (Object o : this) {
hashCode = hashCode * 31;
hashCode = hashCode + o.hashCode();
}
return hashCode;
}